
OS를 새로 설치하고 톰캣도 새로 다운받고백업해놨던 이클립스 워크스페이스를 로드하고 나면 톰캣 설정이 꼬여서 새로운 톰캣 서버를 추가할 수 없게 될때가 있습니다. 그런 상황에서는 http://stackoverflow.com/questions/93900/cant-add-server-to-a-moved-workspace 요로코롬 Window/Preferences/Server/Runtime Environments 가셔서 기존에 있던 톰캣들을 지워주시고 올바른 경로로 새 톰캣 서버를 추가해주시면 됩니다.
스프링에서 mybatis를 설정해서 사용해보기는 했으나, 막상 스프링 없이 사용하려니 버벅여서 정리합니다. mybatis 공식홈페이지에 가면 어떻게 사용해야 하는지 친절하게 설명되어있습니다. http://www.mybatis.org/core/getting-started.html 항상 궁금했던 것인데, ibatis 이름은 왜 mybatis로 바뀌었는가? 그래서 검색해봤습니다. http://ibatis.apache.org http://mybatis.org/about.html 뭔가 정치적인 재미난 얘기가 써있지 않아서 그냥 넘어가겠습니다. 1. 커넥션 생성하기 JDBC를 사용한다고 하니 일단 java.sql.Connection을 생성하고 싶습니다. 연결이 되는지 확인해야 하니까요. 그래서 간단히 유닛테스트를 ..
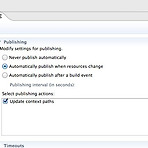 [Tomcat] 프로젝트 import후 tomcat에 publishing되지 않을때
[Tomcat] 프로젝트 import후 tomcat에 publishing되지 않을때
서버 설정이 다음과 같이 되어있기 때문입니다. servers view에서 서버를 더블클릭하면 이런 설정을 볼 수 있는데, 리소스가 바뀌어야 publish하도록 되어 있죠. 개발을 시작한 프로젝트에서는 어차피 만들면서 리소스가 바뀌는데, 임포트 한상태 후 변경되지 않은 클래스 파일은 수정하지 않는 한 바뀌지 않는 거죠. publish되지 않는 다는 것은 tomcat을 실행할 임시 애플리케이션 폴더에 컴파일된 class파일이 복사되지 않는 것을 의미합니다. 이 때 Automatically publish after a built event로 변경한 후 maven build 등으로 build event를 발생시키면 모두 publishing 됩니다. 그 후에는 Automatically publish after a..
두 관련 없는 파일을 비교할 때, 예를 들면, A라는 프로젝트에서 복사 수정한 B라는 프로젝트가 있는데 A 프로젝트의 소스코드에서 변경된 부분을 확인하고 싶을 때는 다음과 같이 하면 됩니다. Package Explorer 등에서 두 파일을 모두 선택합니다. 오른쪽 클릭 또는 Context 버튼을 눌러 컨텍스트 메뉴를 띄웁니다. Compare With > Each Other를 차례로 선택합니다. 출처: Using Eclipse to compare two files
 윈도우에서의 32bit/64bit JVM 간단하고 어설픈 성능 비교
윈도우에서의 32bit/64bit JVM 간단하고 어설픈 성능 비교
OS를 64bit로 설치하면, JVM도 64bit로 설치하고 싶어집니다. 하지만, Eclipse를 비롯한 많은 툴들을 64bit로 사용하려면 불편한 점들이 많습니다. 그래서 64bit JVM의 성능을 테스트 해보기로 했습니다. 64bit jvm으로 검색해보면, 더 많은 메모리를 사용할 수 있지만, 성능에 있어서는 메리트가 없다는 글을 읽어볼 수 있는데, 성능에서 메리트가 없다면, 굳이 64bit JVM을 사용할 필요가 없기 때문입니다. 결론부터 말씀드리자면 잘 모르겠다이지만, 흥미로운 결과를 볼 수 있습니다. 일단 32bit JVM과 64bit JVM을 모두 설치했습니다. 그리고 이클립스도 32bit 버전과 64bit 버전을 모두 다운받아서 압축을 풀어놓았습니다. 두 가지 이클립스를 모두 실행시켜보니, ..
JDBC를 사용하면서 매번 불편했던 점은 ResultSet rset= stmt.executeQuery(sql); 이런 문장을 실행하면, 질의 결과를 모두 받아와서 rset에 넣는 다는 것입니다. 따라서 대용량의 데이터를 한번에 처리할 때는 미리 받아올 데이터의 수를 제한할 필요가 있습니다. 해결책은 바로 Statement 인터페이스의 setFetchSize() 입니다. http://benjchristensen.com/2008/05/27/mysql-jdbc-memory-usage-on-large-resultset/ 을 보고 알게되었는데, 이 글은 MySQL의 경우를 설명하고 있는데, PostgreSQL의 jdbc드라이버에도 사용할 수 있습니다. 2011.12.28 추가. setFetchSize() 메소드의..
 StarUML, 넌 누구냐.
StarUML, 넌 누구냐.
아래는 다 잡설이고, http://cnx.org/content/m15092/latest/ StarUML tutorial 이네요. UML 툴에 익숙하지 않은 저도 쉽게 따라해볼 수 있었습니다. 연구실에서 뭔가를 혼자서 만들때 뭔가 도구를 이용해서 디자인하고 문서화도 했습니다. 그런데, uml 도구라는 것이 쉽지 않더군요. 일단 UML 자체를 모르니. 그래서 당당하게 검색해봤습니다. "UML". 나와라. 오바. UML. 그것은 Unified Modleing Language. 그러나 한국 위키피디아에는 이 항목이 없군요. 그래서 그냥 읽었습니다. 지금부터 영문 위키피디아 내용. UML은 소프트웨어 엔지니어링 분야에서 사용되는 표준화된 일반 목적의 모델링 '언어' 입니다. 특정한 시스템의 추상적 모델을 위한 도..
Personalized Web Search 와 관련해서 ODP(Open Directory Project) 를 참조하고 있습니다. 이 프로젝트에서는 구축된 웹페이지들의 계층구조를 RDF파일로 제공하고 있습니다. 문제는 이 파일이 너무 크다는 것입니다. 1.9GB와 700MB 정도 크기입니다.그래서 간단한 자바 프로그램을 작성하여 파일을 자르기로 했습니다. 싹둑. 검색해보면 '커다란 텍스트 파일을 편하게 잘라주는 프로그램, iHP TxT Split' 와 같은 글들을 찾을 수 있습니다. 어쨌든 연습 삼아 간단하게 자바로 코딩해보았습니다. FileInputStream과 FileouputStream 을 사용해서 하나의 파일을 원하는 크기로(거의) 잘라주는 코드 입니다. package kr.ac.uos.dmlab...
http://commons.apache.org/configuration/ 연구실에서 프로젝트를 할 때, DB 계정 정보 등의 설정 정보 등을 XML파일로 적어놓고 참조하려고 마음을 먹었습니다. 그래서 XML파일 읽는 코드를 한 20줄 짜고, 이 설정 정보를 java.util.Properties 에 저장하여 메모리에 유지하도록 static 하게 변수를 선언하는 등의 작업을 하였으나, 검색해보니 Apache Commons 프로젝트에 Configuration 이라는 컴포넌트가 있습니다. 구글에서 검색하니 http://twit88.com/blog/2007/09/18/xml-configuration-for-java-program/ 에도 간단한 예가 나와있습니다. 어쨌든, http://commons.apache.o..
- Total
- Today
- Yesterday
- PostgreSQL
- openoffice
- Arrays
- subervsion
- 리눅스
- output driver
- pl/java
- OO3
- xml2
- 모토로이
- 다음팟인코더
- userguide
- IcedTea6
- SimpleDateFormat
- yum update
- Eclipse
- Linux
- 병합정렬
- 출력드라이버
- tsclient
- 파란 화면을 보았니
- smplayer
- Java
- Numbering
- gl2
- OpenJDK6
- Fedora 9
- Fedora 8
- GMT
- JavaMail
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |