
 feature exploration logs.
feature exploration logs.
2024.02.11 울산에서 서울 올라가는 SRT 안에서. opendart 에서 "단일회사 전체 재무제표" 들을 KOSPI 회사들에 대해 다운받아서 account id 와 account name 을 확인해보니 표준계정코드 미사용한 경우가 상당비율을 차지하고 있고, 계정 이름도 쓰고 싶은 대로 쓴 것 같아서 많이 사용된 순서대로 확인해보기로 한다. 2024.02.14 다운받은 json 데이터에는 string 타입으로 되어 있어, double 로 변환하면서 음수인 데이터 확인. 당기금액은 94.2% 있는 것을 확인 negative positive sum ratio frmtrm_add_amount 전기누적금액 79718 322809 402527 0.117582983188368 frmtrm_amount 전기금액..
brew 사용해 설치 ~ brew install postgresql ==> Pouring postgresql--14.4.monterey.bottle.tar.gz ==> Caveats To migrate existing data from a previous major version of PostgreSQL run: brew postgresql-upgrade-database This formula has created a default database cluster with: initdb --locale=C -E UTF-8 /usr/local/var/postgres For more details, read: https://www.postgresql.org/docs/14/app-initdb.html To re..
 Mac, Big sur, Wine, WineSkin
Mac, Big sur, Wine, WineSkin
Wineskin Winery 를 잘 사용중이었는데 Big sur 가 업데이트 된 뒤 32bit 바이너리인 wine 을 사용할 수 없게 되었습니다. 그래서 OS 까지 띄워야 하는 VirtualBox 를 사용 중이었는데, m1 맥북에서 VirtualBox 는 사용하지 못할 것으로 보여, wine 에 대한 새로운 소식이 없는지 찾아보았습니다. https://www.reddit.com/r/winehq/comments/j43ziq/wine_on_macos_catalina_and_macos_big_sur/ 이글이 검색되서 가능할 것이라는 힌트를 얻었는데 Wineskin 은 프로젝트가 업데이트가 안되고 있었고 https://github.com/Gcenx/WineskinServer 를 설치해보니 잘 실행되었습니다. 현..
의존성 /* * This file was generated by the Gradle 'init' task. * * This generated file contains a sample Scala library project to get you started. * For more details take a look at the 'Building Java & JVM projects' chapter in the Gradle * User Manual available at https://docs.gradle.org/7.1/userguide/building_java_projects.html */ plugins { // Apply the scala Plugin to add support for Scala. id 's..
팀에 자바 개발자가 오셔서 카프카 파이프라인을 go 에서 java 로 변경하려고 하는데, 제가 작업할 때는 더 익숙한 scala 를 사용하려고 했는데( 변수 타입 써주기 귀찮아요 ) gradle 을 빌드도구로 쓰려다 보니 방법을 찾다가 아래 글을 찾아서 기록을 남깁니다. http://www.legendu.net/misc/blog/scala-with-gradle-in-intellij/ 프로젝트 디렉터리를 만들고 해당 디렉터리로 들어갑니다. mkdir some_project cd some_project gradle 명령어로 초기화합니다. gradle init --type scala-library 아래와 같은 화면에서 DSL 파일의 언어, 프로젝트 이름, 패키지 이름 등을 지정해줍니다. Starting a G..
m1 맥북에서 tensorflow 성능이 훌륭하다는 글, 맥북에는 intel cpu 가 달려있지만 조금더 성능이 좋아진다고 하니 시도해보자 blog.tensorflow.org/2020/11/accelerating-tensorflow-performance-on-mac.html Accelerating TensorFlow Performance on Mac Accelerating TensorFlow 2 performance on Mac blog.tensorflow.org 우선 pyenv 로 virtual env 를 설치해보자 pyenv git: github.com/pyenv/pyenv pyenv virtualenv git: github.com/pyenv/pyenv-virtualenv brew update # p..
ㅕgithub.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/master/docs/user-guide.md User Guide spark 를 사용하기 위한 Kubernetes operator 를 빌드, 설치, 예제 앱 실행을 위해서는 Quick Start Guide 참조 SparkApplication, ScheduledSparkApplication 의 API 정의는 API Specification 을 참조 kubesctl 에 추가적인 기능을 제공하는 sparkctl 을 제공하고 있음. sparkctl 에 대한 문서는 README 참고 Using a SparkApplication SparkApplication 을 YAML 파일에 명세하고, kubectl 또는 s..
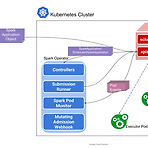 Kubernetes Operator for Apache Spark Design
Kubernetes Operator for Apache Spark Design
github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/master/docs/design.md#architecture 오역, 오해 주의 Introduction 독립 스케쥴러, Mesos, yarn 에 이어 스파크 2.3 부터 쿠버네티스는 스파크의 공식적인 스케쥴러가 되었다. 쿠버네티스 위에 스파크 클러스터를 구성하고, 그 스파크 클러스터에 어플리케이션(이하 앱)을 제출하는 방식과 비교해서, 쿠버네티스 자체를 스케쥴러를 사용하는 것은 여러 중요한 장점이 SPARK-18278 에서 논의되었고 많은 진전이 있었다. 그런데 쿠버네티스에서 실행하기 위해 제출하고, 상태를 추적하는 등의 스파크 앱의 생명주기를 관리하는 방식은 Deployment, DaemonSet, ..
pane 간에 텍스트 복사하기vertical 하게 pane 을 나누면 텍스트를 복사하기 불편하다. https://unix.stackexchange.com/questions/58763/copy-text-from-one-tmux-pane-to-another-using-vim 맥에서 linux 에 접속한 상황1. ctrl + B + [ scroll mode로 전환2. 화살표키로 복사 시작위치 이동3. ctrl + space 복사할 텍스트 지정 시작4. 화살표키로 복사 끝 위치로 이동5. esc + w 복사6. 다른 pane 으로 가서 붙여넣을 위치로 이동 7. ctrl + B + ] 붙여넣기
IntelliJ 소소한 팁들... 메소드 찾기 ( 이클립스의 ctrl + o 와 같음) cmd + F12
- Total
- Today
- Yesterday
- SimpleDateFormat
- openoffice
- smplayer
- Numbering
- GMT
- pl/java
- 병합정렬
- 리눅스
- JavaMail
- Fedora 8
- PostgreSQL
- OO3
- Arrays
- OpenJDK6
- 출력드라이버
- 모토로이
- xml2
- subervsion
- Linux
- Fedora 9
- yum update
- IcedTea6
- 다음팟인코더
- tsclient
- 파란 화면을 보았니
- gl2
- Eclipse
- Java
- userguide
- output driver
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |